Pipeline
Overall pipeline of our method in three parts: Encoding, Feature Retrieval and Decoding.
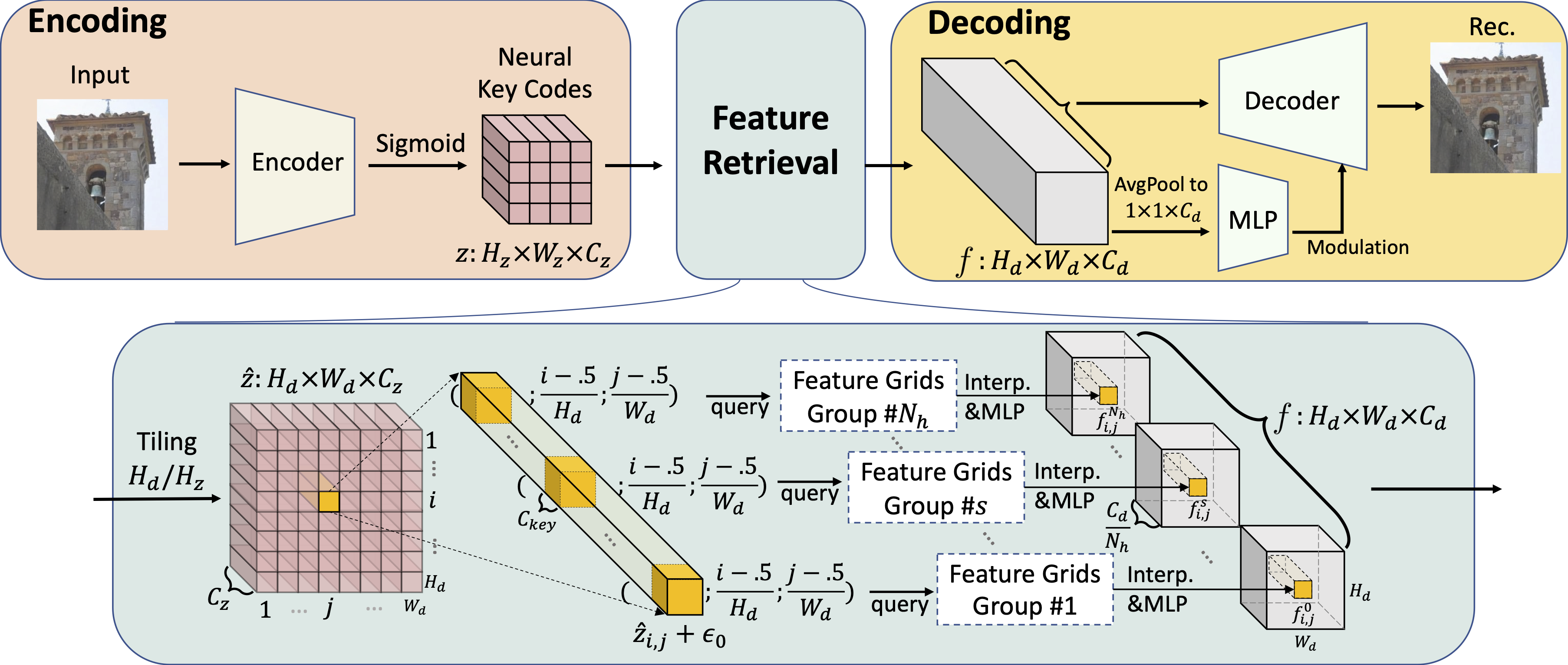






Overall pipeline of our method in three parts: Encoding, Feature Retrieval and Decoding.
Our largest model (code size 16 × 16 × 16) has only 10M more parameters (≈ 24% increase) than those of the corresponding VQGAN and RQ-VAE models. However, our model outperforms VQGAN and RQ-VAE across all metrics, showing 55% and 41% improvements in LPIPS, respectively. In terms of computational costs, our method requires ≈ 50% fewer GFlops due to its smaller decoder and the efficiency gained from utilizing the multi-scale feature grids.

Reconstruction metrics on the validation splits of FFHQ and LSUN-Church dataset.

Trainable parameters and computational load of decoders. An * indicates total number of parameters in feature grids and ‡ refers to total computational cost of decoding and feature retrieval from feature grids.
We achieve the state-of-the-art CLIP-FID than others (≈44% lower than Projected GAN, ≈32% lower than StyleGAN2, and ≈29% lower than LDM) while maintaining competitive on all other metrics. Moreover, the precision score of our generated images is significantly higher than others, indicating a substantial reduction of low-quality samples in our results, while our recall is the second best in LSUN-Church and is almost the same as StyleGAN2 in FFHQ dataset.

Quantitative results of generation on LSUN-Church dataset. Our relaxed precision (Config d) method is adapted to two distinct noise schedulers (Config a,b) and gets record low CLIP-FID in Config b + d, while Config a + c (KL-reg with min-snr noise scheduler) gets much worse results. * denotes that we measure the metrics of Projected GAN using the checkpoint provided from the official Projected GAN Github repository. Underlined numbers are the second best results.
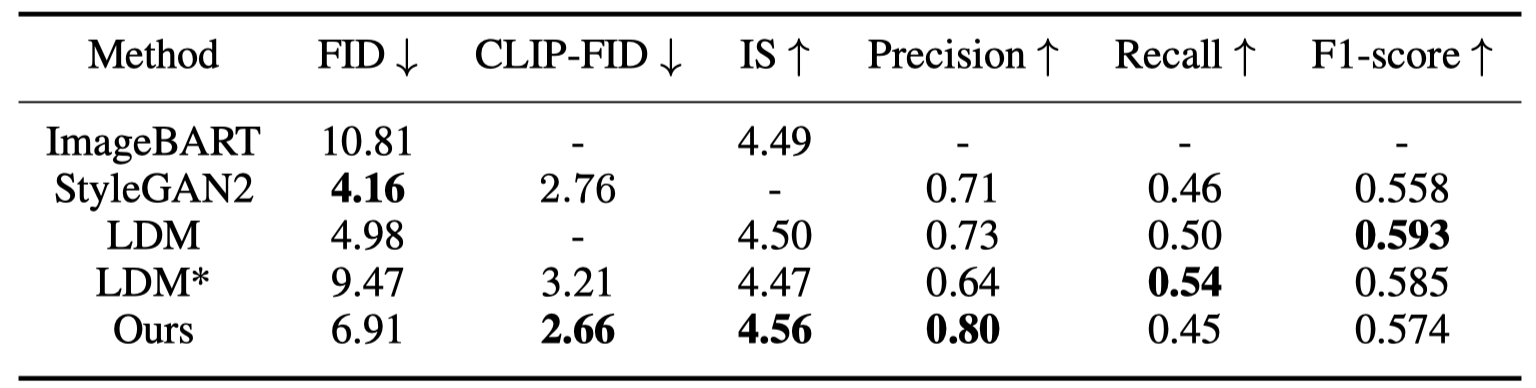
Quantitative results of generation on FFHQ dataset. * denotes the results calculated on publicly released checkpoint by LDM author on Github.
Although our method has much higher precision scores than previous methods, we show the nearest neighbour search by LPIPS to demonstrate that our generated samples are unique and not mere retrievals from the training dataset. In the following images, the leftmost images in each row are generated images from our method and the rest images in each row are the nearest neighbour search results.

